



Secure your Postgres analytics in minutes.
Fork our Postgres SQL Analytic Toolkit, lock it down with least-privilege roles, tailor it to your schema, and deploy on Arcade in under 6 minutes.
See Example →
One of the most popular use-cases for AI/LLM Agents is exploring and activating data in your SQL databases and warehouses. How can you build safe and reliable agents? Let’s explore the space.
Start with Boundaries, Not Prompts
Prompting tells the model what you want, not what it’s allowed to do. Think of a prompt like an intent- helpful for UX, but never a security guarantee. Real enforcement lives a layer deeper: in the database engine itself or a narrowly scoped service tier you fully control.
To get this right, you will need:
- Purpose‑built roles - create one DB role per toolkit so your permission story is self‑documenting.
- Limit surface area
- Access - If your agent does not need write access, do not grant it.
- Tables - expose only the ones the agent genuinely needs.
- Columns - omit ssn, password_hash, and other PII entirely.
- Rows - enable Row‑Level Security (RLS) so agents see only their slice of data.
- Pin connections to those roles - use a connection pool that the LLM cannot access, via a remote tool server. Never grant the agent the ability to modify this with commands like SET ROLE. Furthermore, to speed up your agent, keep a connection pool alive that was created when the agent booted up, and don’t let the agent change it.
PostgreSQL example:
ALTER TABLE orders ENABLE ROW LEVEL SECURITY;
CREATE POLICY region_policy ON orders
USING (region = current_setting('app.current_region'));
GRANT SELECT (id, customer_id, total_cents, region)
ON orders TO ai_reporting;Other engines have similar primitives: Snowflake’s Secure Views, BigQuery’s Authorized Views, and SQL Server’s Dynamic Data Masking all let you enforce the same principle—least privilege by default, enforced where the data lives.
Creating AI tools (e.g. MCP servers) with overly permissive access is why recent security issues have occurred (e.g.). Don’t do that!
When building out your tool, consider how the permissions of the database account and the roles of your end-users relate. There are a few options:
- Single User: The agent is single-user, and the agent’s database access is exactly the same as the user’s access. In this use case, storing the connection string for the database as an environment variable would work.
- Single Role: The agent is multi-user, and the agent’s database access is exactly the same for all users of the agent. E.g. the “finance agent” will only be used by members of the finance department, or the "analytics agent” has access to tables that the whole company can see. Once again, storing the connection string for the database as a global environment is appropriate.
- Heterogeneous Roles: Multiple types of users will be using agents, each with different access. In this case, your agent will need to manage multiple connections for each type of user. Perhaps each user is required to store their own connection string as a secret, or you’ll be looking up each user’s permissions in a system like DreamFactory or a similar entitlement server.
Operational or Exploratory Tools?
It is important to differentiate between these two primary types of SQL tools for AI agents, as their design and security considerations vary. The two types of SQL tools, broadly speaking, can be classified as “Operational” and “Exploratory”. Operational tools have very clearly defined use-cases, and can even safely modify data. Exploratory tools are for data exploration and reporting, and need to support unknown use-cases and expansive schemas.
Operational Tools: Precision and Control
Operational SQL tools are designed for specific, often transactional, interactions with the database. They are typically used for tasks that involve data modification (inserts, updates, and even deletes) or highly structured data retrieval. The emphasis here is on precision, predictability, and safety.
Agents are more susceptible to SQL injection attacks than traditional software due to an added layer of interpretation if you let the LLM write any part of the query. You need to guard against attacks just like any other software application interacting with a database. You shouldn’t be letting your LLM write SQL statements whenever possible. What you should be doing instead is building Operational Tools with the following properties:
- Prepared Statements: Always utilize prepared SQL statements to prevent SQL injection vulnerabilities. The AI agent should provide parameters that are then bound to the pre-compiled statement, rather than constructing raw SQL queries.
- Specific Methods and Input Validation: Each operational tool should expose clearly defined methods (functions) that the AI agent can call. These methods must include robust input validation, ensuring that all incoming data conforms to expected types, formats, and ranges.
- Enumerate Allowed Values: For fields with a limited set of valid inputs, use enums or lookup tables to restrict the AI agent's choices. This prevents the generation of invalid or malicious data.
- Least Privilege: As previously discussed, these tools must operate with the absolute minimum database permissions required.
Examples of Operational Tools
Operational tools have type descriptions like:
# An example of a typed operational read tool
@tool(requires_secrets=["DATABASE_CONNECTION_STRING"])
async def count_new_users_of_app(
context: ToolContext,
aggregation_window: Annotated[AggregationWindowEnum, "The time range to group new users by. Default: 'day'"] = AggregationWindow.day, # Arcade will expand the options of AggregationWindowEnum into the prompt automatically
exclude_internal_users: Annotated[bool, "Should we ignore internal users? Default: True"] = True
limit: Annotated[int, "The number of rows to return. Default: 100"] = 100,
) -> int:
"""
Count the number of new users within a time window
"""Which produces a query like:
SELECT date_trunc($1, created_at) AS period, COUNT(*) AS user_count
FROM users
WHERE internal = false
GROUP BY period
ORDER BY period DESC
LIMIT $2 sqAnd
# An example of a safe tool which would modify the database
@tool(requires_secrets=["DATABASE_CONNECTION_STRING"])
async def update_user_payment_plan(
context: ToolContext,
user_id: Annotated[str, "The user ID to modify"],
payment_plan: Annotated[PaymentPlanEnum, "The payment plan for the user"], # Arcade will expand the options of PaymentPlanEnum into the prompt automatically
) -> PaymentPlanEnum:
"""
Update the payment plan for a specific user.
"""Which produces a query like:
UPDATE users SET payment_plan = $1 WHERE id = $2 LIMIT 1Note the ToolContext argument in the examples above. That’s Arcade’s way of passing secrets and user information into the tool without having it go through the (unsafe) LLM. You never want something as sensitive as a database connection string or password to be available to the LLM - it might display it, leak it, or worse, train on it. Learn more about ToolContext here.
Exploratory Tools: Exploration and Insights
Exploratory SQL tools, in contrast, are designed for querying and extracting insights from data. The most common use case is to enable internal users within your organization to access your data warehouse. A data warehouse is a massive database (commonly Snowflake or Databricks) that contains all of the data from all of the tools your company uses. It is kept in sync via an ELT/ETL tool like Airbyte.
The primary constraint for these tools is that they must be read-only. This fundamental restriction significantly reduces the security surface area.
- Read-Only Enforcement: The database roles associated with exploratory tools must explicitly have `SELECT` privileges only, with no `INSERT`, `UPDATE`, or `DELETE` permissions. Well-written SQL tools will also enforce that only SELECT queries are allowed to be executed. Again, Agents are even more susceptible to SQL Injection attacks! Prevent them at the connection level.
- Schema Understanding: Your agents will need to know what tables exist and what they are for. The best pattern would be to load descriptions of the tables you need into the context ahead of time, along with any reference metadata that is available. Perhaps you have a Semantic Layer (e.g. dbt or Cube) you can use, or table annotations which can be loaded from your database. Failing that, describe your schema in plain text.
- Table Descriptions: To enable effective querying by the AI agent, provide clear and concise descriptions of the tables and their columns. It is unlikely that all of your tables will be needed for all use-cases (and that will waste tokens), so the LLM/Agent should be encouraged to learn the schema of the relevant tables before trying to query them. A “Look -> Plan -> Query” workflow works great.
- Querying Best Practices: While exploratory tools can be more general, encourage practices such as:
- Limiting Result Sets: Require a `LIMIT` clause in its queries to prevent excessively large result sets.
- Specific Column Selection: Encourage selecting only necessary columns rather than `SELECT *`.
- `EXPLAIN ANALYZE` (for development/debugging): While not for the LLM to run directly in production, explaining the query plan can help in tool development.
- RetryableToolErrors for Workflow Learning: Implement custom error types like RetryableToolError when the LLM attempts an invalid exploratory query (e.g. hallucinating columns that don’t exist). This signals to the LLM that it needs to inspect the available tables and their descriptions before attempting the next query, teaching it a more robust workflow. Learn more about retryable tool errors here.
Examples of Exploratory Tools
A good set of exploratory SQL tools for data exploration might look like:
Discover Schema:
@tool(requires_secrets=["DATABASE_CONNECTION_STRING"])
async def discover_schemas(
context: ToolContext,
) -> list[str]:
"""
Discover all the schemas in the postgres database.
"""
@tool(requires_secrets=["DATABASE_CONNECTION_STRING"])
async def discover_tables(
context: ToolContext,
schema_name: Annotated[
str, "The database schema to discover tables in (default value: 'public')"
] = "public",
) -> list[str]:
"""
Discover all the tables in the postgres database when the list of tables is not known.
ALWAYS use this tool before any other tool that requires a table name.E.
"""Get Table Schema:
@tool(requires_secrets=["DATABASE_CONNECTION_STRING"])
async def get_table_schema(
context: ToolContext,
schema_name: Annotated[str, "The database schema to get the table schema of"],
table_name: Annotated[str, "The table to get the schema of"],
) -> list[str]:
"""
Get the schema/structure of a postgres table in the postgres database when the schema is not known, and the name of the table is provided.
This tool should ALWAYS be used before executing any query. All tables in the query must be discovered first using the <DiscoverTables> tool.
"""Execute Select Query:
@tool(requires_secrets=["DATABASE_CONNECTION_STRING"])
async def execute_select_query(
context: ToolContext,
select_clause: Annotated[
str,
"This is the part of the SQL query that comes after the SELECT keyword wish a comma separated list of columns you wish to return. Do not include the SELECT keyword.",
],
from_clause: Annotated[
str,
"This is the part of the SQL query that comes after the FROM keyword. Do not include the FROM keyword.",
],
limit: Annotated[
int,
"The maximum number of rows to return. This is the LIMIT clause of the query. Default: 100.",
] = 100,
offset: Annotated[
int, "The number of rows to skip. This is the OFFSET clause of the query. Default: 0."
] = 0,
join_clause: Annotated[
str | None,
"This is the part of the SQL query that comes after the JOIN keyword. Do not include the JOIN keyword. If no join is needed, leave this blank.",
] = None,
where_clause: Annotated[
str | None,
"This is the part of the SQL query that comes after the WHERE keyword. Do not include the WHERE keyword. If no where clause is needed, leave this blank.",
] = None,
having_clause: Annotated[
str | None,
"This is the part of the SQL query that comes after the HAVING keyword. Do not include the HAVING keyword. If no having clause is needed, leave this blank.",
] = None,
group_by_clause: Annotated[
str | None,
"This is the part of the SQL query that comes after the GROUP BY keyword. Do not include the GROUP BY keyword. If no group by clause is needed, leave this blank.",
] = None,
order_by_clause: Annotated[
str | None,
"This is the part of the SQL query that comes after the ORDER BY keyword. Do not include the ORDER BY keyword. If no order by clause is needed, leave this blank.",
] = None,
with_clause: Annotated[
str | None,
"This is the part of the SQL query that comes after the WITH keyword when basing the query on a virtual table. If no WITH clause is needed, leave this blank.",
] = None,
) -> list[str]:
"""
You have a connection to a postgres database.
Execute a SELECT query and return the results against the postgres database. No other queries (INSERT, UPDATE, DELETE, etc.) are allowed.
ONLY use this tool if you have already loaded the schema of the tables you need to query. Use the <GetTableSchema> tool to load the schema if not already known.
The final query will be constructed as follows:
SELECT {select_query_part} FROM {from_clause} JOIN {join_clause} WHERE {where_clause} HAVING {having_clause} ORDER BY {order_by_clause} LIMIT {limit} OFFSET {offset}
When running queries, follow these rules which will help avoid errors:
* Never "select *" from a table. Always select the columns you need.
* Always order your results by the most important columns first. If you aren't sure, order by the primary key.
* Always use case-insensitive queries to match strings in the query.
* Always trim strings in the query.
* Prefer LIKE queries over direct string matches or regex queries.
* Only join on columns that are indexed or the primary key. Do not join on arbitrary columns.
"""You can see an example exploratory Postgres Arcade toolkit here.
Remember above how we discussed schema understanding? Note how these general purpose tools lack that - which means that they won’t be as effective as they could be. Imagine that each of these tools could be given additional context about the structure of your database:
- Which are the final/gold tables in your Medallion Architecture, and therefore the LLM should prefer them for most queries?
- Which tables are the most useful to analysis in general (e.g. users or accounts?).
- Which types of questions prefer which tables (e.g. financial questions should start with the normalized_accounts tables).
- Any “translations” the LLM might need to find your data (e.g. all payment and transaction information is in USD, listed in cents).
Hinting official preferences to the LLM will save a lot of time and tokens!
On Dynamic Schema Loading:
As your schema grows, you will encounter performance and context limitations - you won’t be able to pre-load your whole schema into the LLM - it will be too large. When that happens, you’ll need to start looking into dynamically loading your schema as needed via “discovery” tools, or memory compression techniques.
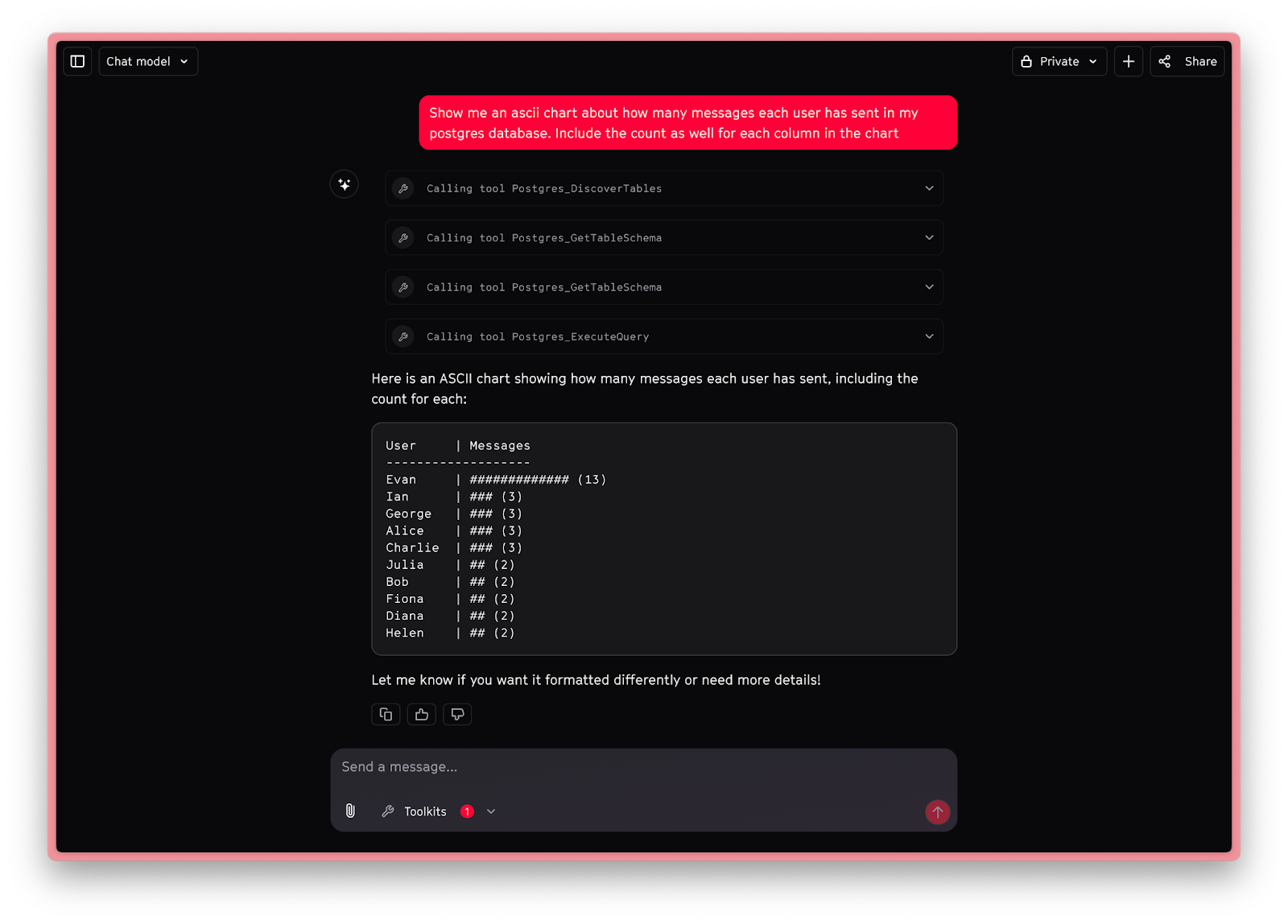
Consider the example at the start of this article. A multi-turn agent used the hints in our tools to properly build out the tool-calling workflow for itself:

The Tools as defined above were how we prompted the LLM to inspect the database and find only the tables it needed, and then load their schema - saving time and tokens.
Customization vs. Generality
While general SQL querying tools can be useful, remember that tools specifically designed for a use case will be more reliable and less prone to errors than allowing the LLM to construct arbitrary SQL queries. Yes, the end goal of all Exploratory tools is to convert them into Operational tools once you have your query dialed in. We are moving tools up from the "service" tier to the "workflow" tier, which has better quality and lower latency.
We can classify the steps on this journey and some of the changing design criteria:
- Exploratory (service tier):
- Low accuracy tools which require human hand-holding
- Highly general tools which require elevated permissions
- low token count
- heavy LLM reliance
- Likely a low number of tools for the LLM to choose from
- Example:
execute_query()
- Hybrid:
- More accurate,
- Still general, but limited to a specific domain,
- high token count
- Example
GetRecentSalesWins()
- Operational (workflow tier)
- Very accurate, appropriate for operationalization
- Highly specific and can work with tightly scoped permissions
- very high token count,
- low LLM reliance
- Likely a high number of tools for the LLM to choose from
- Example:
GetRecentSalesWinsBySalesperson()
What’s Next?
In closing, it is possible to build effective and safe SQL tools for Agents. But, you need to be clear about what tools the agent can call, and create specific boundaries to keep them safe.
Secure your Postgres analytics in minutes.
Fork our Postgres SQL Analytic Toolkit, lock it down with least-privilege roles, tailor it to your schema, and deploy on Arcade in under 6 minutes.
Get started now →




