




It’s popular to test Large Language Models (LLMs) by asking them to solve difficult puzzles, like multiplying huge numbers. These tests are interesting research benchmarks, but they can miss something important: real-world usefulness. When was the last time you asked a coworker to multiply a 20-digit number in their head, without a calculator?
Real-world usefulness is not always well-represented by artificial benchmarks. Throughout history, humans have invented tools to boost their abilities: carpenters use saws, accountants use calculators. Tools help humans do more and work faster, and tools help LLMs in the same way.
If you're building products powered by AI, it makes sense to let LLMs focus on what they're good at—language and reasoning—while delegating specialized tasks, like tricky calculations, to dedicated tools.
What happens when LLMs have tools?
The idea of giving AI access to tools isn't new. Early approaches focused on tools glued together by simple scripts. That simple approach evolved into AI agents, with a “brain” (the LLM) directing different tools to perform real tasks. Without tools, an LLM is stuck having conversations. Give it tools, and suddenly it can actually get things done.
At Arcade, we wanted to recreate the large multiplication experiment using tools, but with a twist: we used OpenAI’s GPT-3.5 Turbo, the oldest model that can call functions (tools). It's not the latest or most powerful, and is pretty terrible at multiplication on its own. But by giving it a Multiply tool, it nailed the challenge perfectly:
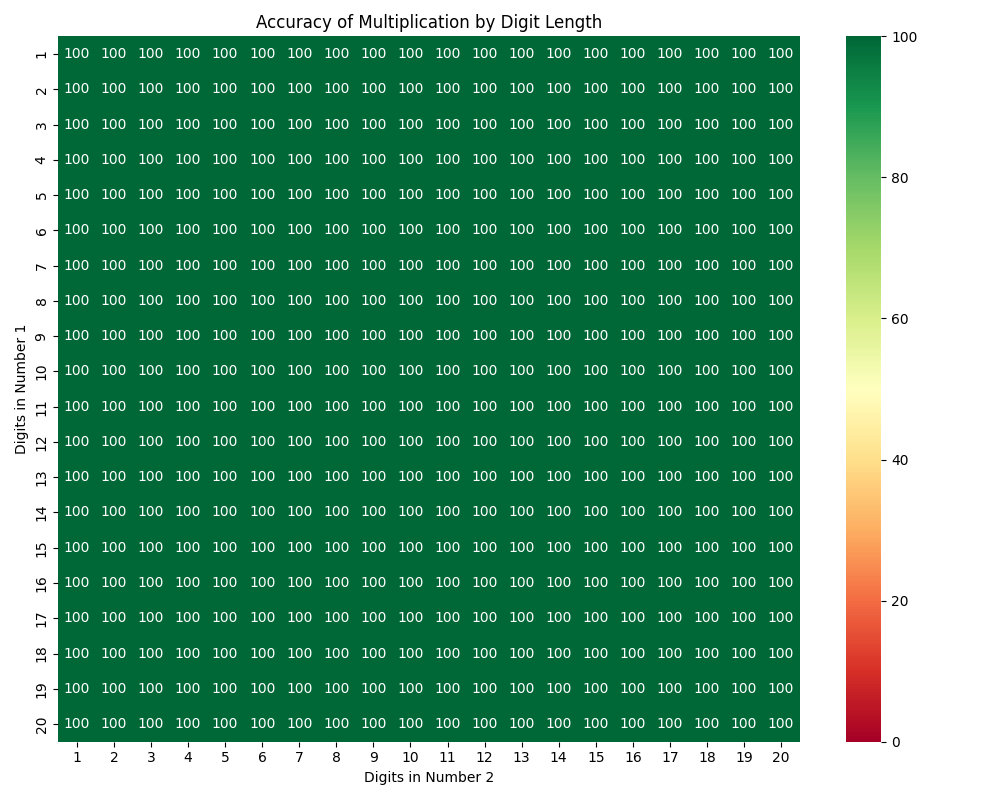
You might say, “Of course it succeeded—you gave it a calculator with a single button!” That's fair. If the LLM has a bigger calculator with more “buttons”, will it still select and use the right tool?
Spoiler alert: Yes! Even when we expanded the experiment to include 20 different math tools, the model still got every answer right. We used Arcade’s tool evaluation framework to test and tune our math tools, which helps models (especially smaller ones) perform well.
This result doesn’t mean that 3.5 Turbo is “smarter” than newer models like OpenAI o1 or Claude 3.7 Sonnet. But it does show that giving LLMs a set appropriate tools can greatly increase their real-world usefulness. The Berkeley Function Calling Leaderboard has fantastic data on how different models behave when given many tools to choose from.
Become a tool-calling pro
Interested in experimenting for yourself? Check out our code to replicate the results.
Just like people, LLMs can perform much better when equipped with good tools. On their own, powerful reasoning models like o1-mini and o1-preview struggle to do big math. But when given a calculator tool, GPT 3.5 Turbo solves the problem cheaper, faster, and with zero mistakes. For context, using o1-mini is expensive ($1.10/$4.40 per million input/output tokens), while 3.5 Turbo is significantly cheaper ($0.50/$1.50 per million input/output tokens) – about 40% of the price of o1-mini and only 3% of the price of o1!
Not too bad for a model released 3 years ago, huh? If you're deploying AI products at scale, this is a critical consideration to make when designing your systems.
At Arcade, we're excited about a future where AI agents use tools to solve real-world problems effectively. If you're developing AI-powered products and want your models to do useful things, try out Arcade – it’s the simplest, most powerful way to give your AI models the tools they need and evaluate them for real-world effectiveness.
P.S. - Curious how GPT-3.5 Turbo does without tools? It doesn't look good.





